笔记:超大数据下最优抽样理论与方法
在大数据的研究中,往往研究的数据量极大,我们并不需要使用其全部数据。但问题是我们应当使用哪些数据作为研究对象呢?
在大数据的研究中,往往研究的数据量极大,我们并不需要使用其全部数据。但问题是我们应当使用哪些数据作为研究对象呢?
广义线性模型扩展了线性模型的框架,包含了非正态因变量的分析。logisitic回归的因变量为类别型,比如二值变量(是/否、通过/未通过)和多分类变量(好/...
logistic回归logistic回归与线性回归并成为两大回归。logistic回归解释起来直接就可以说,如具有某个危险因素,发病风险增加多少倍,听起来...
分布执行和分布结果的可视化是我喜欢使用Jupyter Notebook的主要原因。为了将软件包安装与系统隔离开来,如何在virtualenv中使用Jupyter Notebook呢?
最近在研究生存分析,发现R语言中做没有因子(即自变量x)的生存分析时,类似这种语句`surv.all <-survfit(Surv(month,status)~1)`,右边的括号要写`~1`才能运行,这是为什么呢,其中的`~1`又是什么意思?
大家还记得江湖中那个传说吗?C-index就是ROC曲线下面积AUC?
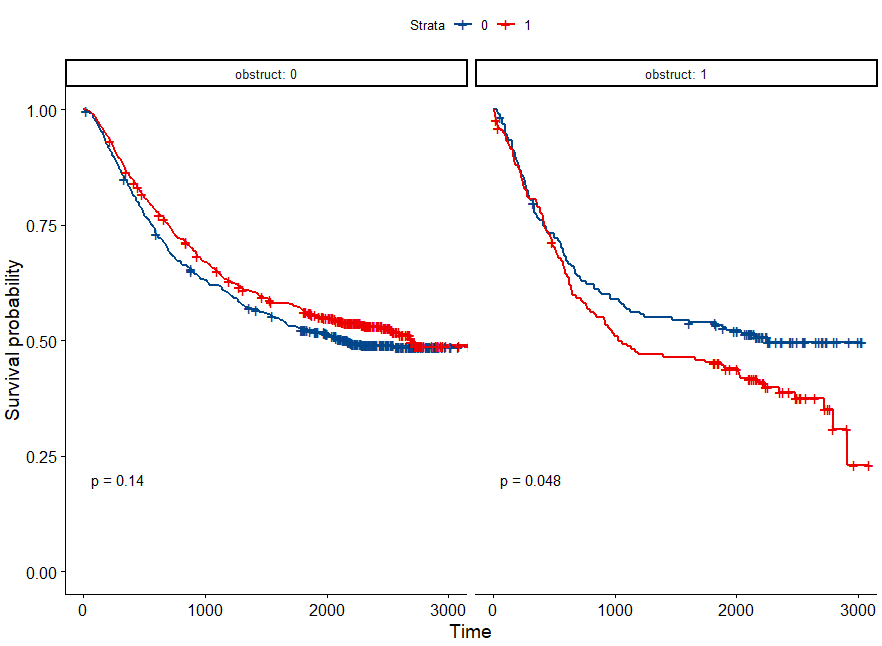
1. 导入包绘制分组Kaplan-Meier生存曲线需要用到的R包:survminer和survival ,如果没有请安装。 install.pac...
Jupyter Notebook是前身为Ipython的一种在线编译器,因此要让Jupyter Notebook能够支持R语言,需要安装一个较为关键的包
世上无难事,只要隔硬黎。——黄子华
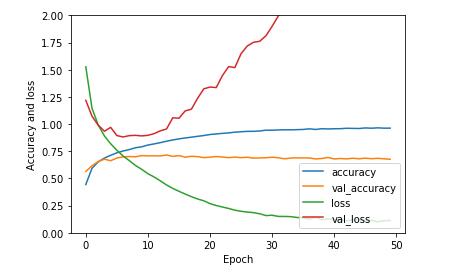
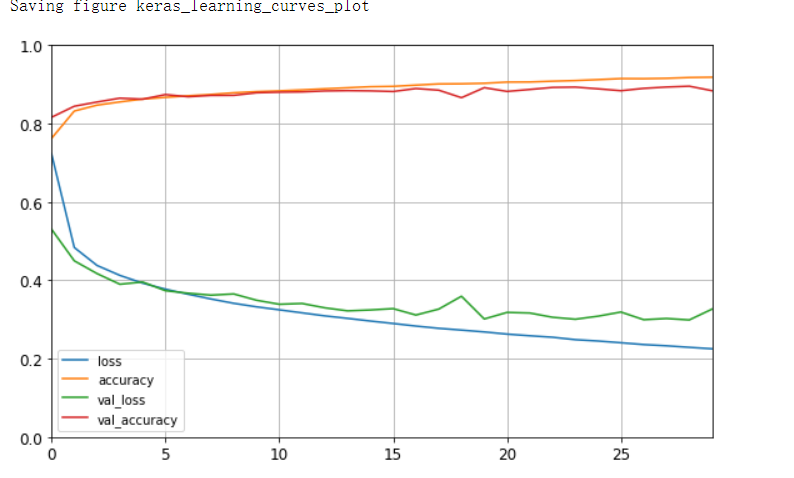
loss:训练集损失值accuracy:训练集准确率val_loss:测试集损失值val_accruacy:测试集准确率以下5种情况可供参考:train ...